Nhờ anh/chị hổ trợ giúp em cần làm 1 File excel tổng hợp Trong tháng 7 có 30 File - Gộp thành 1 File với 30 Sheet chỉ sử dụng Sheet có dữ liệu Pivot sẵn . Tính tổng COD và trung bình Trọng lượng tính phí . Em có làm mẫu tham khảo như vậy nhưng làm từng File thì sẻ mất thời gian . Nên nhờ anh/chị cao nhân hướng dẫn em có phương pháp nào nhanh . em có tìm hiểu công cụ Combine Data trong Excel nhưng ko rỏ phương pháp . Phiền anh chị hướng dẫn em kèm 1 File mẫu để em tham khảo . Em xin cảm ơn rất nhiều --- Dead line dí quá T__T
Em bổ sung luôn giải pháp bằng Pythol . COD đã chỉnh sửa để xuất đúng yêu cầu theo mẫu em mong muốn .
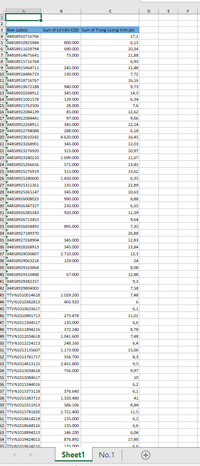
Giữ nguyên sheet Pivot (không lấy dữ liệu gốc, chỉ lấy dữ liệu tổng hợp sẵn).
Gộp thành 1 file Excel mới với:
Mỗi ngày = 1 sheet (tên sheet theo tên file: 01.07, 02.07, … 30.07).
Mỗi sheet chứa đúng bảng Pivot đã có trong file gốc.
Thêm 1 sheet Tổng hợp cuối cùng:
Cột: Ngày – Tổng COD – Trung bình Trọng lượng tính phí.
Tất cả dữ liệu trong mọi sheet đều được căn giữa (center).
Vẫn giữ auto-fit chiều rộng cột.
Các sheet ngày giữ đầy đủ dữ liệu, chỉ xoá dòng “Unnamed”.
Sheet Tổng hợp giữ nguyên 3 cột, hiển thị số có dấu phẩy + trọng lượng 2 chữ số thập phân.
Em gửi kèm File Pythol và File excel mẫu sau khi xuất để a/e tham khảo
A/e tải về mở bằng NOTE chỉnh đường dẫn trong đoạn code :
folder = Path(r"Đường dẫn Folder lưu trữ dữ liệu cần gộp")
files = sorted(folder.glob("*.xlsx"))
Rồi chạy là auto - ae có thể tham khảo Chat GPT nếu muốn điều chỉnh thêm phù hợp . Mong sẻ có ích với a/e nào cần . Xin chân thành cảm ơn
Bài đã được tự động gộp:
import pandas as pd
from pathlib import Path
from datetime import datetime
from openpyxl.utils import get_column_letter
from openpyxl import load_workbook
from openpyxl.styles import Alignment
# Thư mục chứa file Excel theo ngày
folder = Path(r" đường dẫn Folder chứa dữ liệu cần gộp ")
files = sorted(folder.glob("*.xlsx"))
def find_header_row(df, search_rows=15):
for i in range(min(search_rows, len(df))):
row = df.iloc.astype(str).fillna("")
text = " ".join(row.tolist()).lower()
if ("row labels" in text) or ("sum of" in text) or ("cod" in text) or ("trọng" in text):
return i
return df.head(search_rows).notna().sum(axis=1).idxmax()
def get_day_name(p: Path):
parts = p.stem.split(".")
return parts[0] + "." + parts[1] if len(parts) >= 2 else p.stem
summary_rows = []
with pd.ExcelWriter(output_file, engine="openpyxl") as writer:
for file in files:
day_name = get_day_name(file)
try:
raw = pd.read_excel(file, sheet_name=0, header=None)
# Xoá các dòng chứa "Unnamed"
mask_unnamed = raw.astype(str).apply(
lambda s: s.str.contains("Unnamed", case=False, na=False)
).any(axis=1)
raw = raw[~mask_unnamed].reset_index(drop=True)
if raw.empty:
pd.DataFrame().to_excel(writer, sheet_name=day_name, index=False)
summary_rows.append([day_name, 0, 0.0])
continue
# Tìm Grand Total trong df gốc (trước khi format chuỗi)
df_raw = raw.iloc[hrow + 1:].copy()
df_raw.columns = header
df_raw = df_raw.reset_index(drop=True)
if not gt_mask.any():
summary_rows.append([day_name, 0, 0.0])
else:
gt = df_raw[gt_mask].iloc[0]
# Xác định cột COD và Trọng lượng
def find_col(cols, keywords):
for c in cols:
sc = str(c).lower()
if any(k in sc for k in keywords):
return c
return None
# Format COD có dấu phẩy trong tất cả các sheet
cod_col = next((c for c in df.columns if "COD" in str(c).upper()), None)
if cod_col:
df[cod_col] = pd.to_numeric(df[cod_col], errors="coerce")
df[cod_col] = df[cod_col].fillna(0).astype(int).map("{:,}".format)
# Ghi sheet đã làm sạch
df.to_excel(writer, sheet_name=day_name, index=False)
# Tạo sheet "Tổng hợp" (giữ cả 3 cột)
summary_df = pd.DataFrame(summary_rows, columns=["Ngày", "Tổng COD", "Trọng lượng tính phí"])
summary_df["Tổng COD"] = summary_df["Tổng COD"].map(lambda x: f"{x:,.0f}")
summary_df["Trọng lượng tính phí"] = summary_df["Trọng lượng tính phí"].map(lambda x: f"{x:,.2f}")
# Auto-fit độ rộng cột + canh giữa dữ liệu
wb = load_workbook(output_file)
for ws in wb.worksheets:
for col_cells in ws.columns:
width = 0
for cell in col_cells:
if cell.value is not None:
width = max(width, len(str(cell.value)))
# Căn giữa
cell.alignment = Alignment(horizontal="center", vertical="center")
ws.column_dimensions[get_column_letter(col_cells[0].column)].width = width + 2
wb.save(output_file)
Em bổ sung luôn giải pháp bằng Pythol . COD đã chỉnh sửa để xuất đúng yêu cầu theo mẫu em mong muốn .
Giữ nguyên sheet Pivot (không lấy dữ liệu gốc, chỉ lấy dữ liệu tổng hợp sẵn).
Tôi nghĩ rằng bạn đã biết dùng pivot table thì tổng hợp bằng pivot table luôn chứ? Mà hễ tổng hợp bằng pivot thì 1 bảng duy nhất hàng dọc chắc chắn dễ hơn nhiều bảng ở nhiều sheet.
Ghi chú:
- Bài 1 bạn không gởi file hoặc hình ảnh cái tổng hợp, biết hình dạng thế nào mà lấy tối ưu? Làm sao mà biết "mẫu em mong muốn" là cái gì?
- Trong 3 file bạn gởi có 1 file không phải pivot table và PQ phải tốn thêm 1 dòng lệnh lọc.
- Canh giữa là 1 điều tối kỵ (riêng tôi coi là nhảm nhí)
- Dữ liệu có dòng “Unnamed” cần phải bỏ thì chỉ mình bạn biết. Dù vậy dùng PQ thì muốn bỏ cái gì chẳng được.
- Dùng PQ thì có thể làm ngay khi chỉ có 1 số ít ngày có dữ liệu (có file). Khi có thêm dữ liệu chỉ cần thêm file vào và refresh.
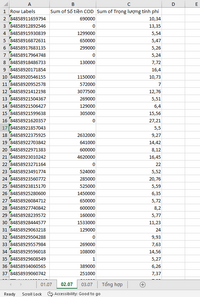
Dùng cho các bạn cùng "ý" sử dụng Power query. Giờ mới có bảng tổng hợp mẫu nên PQ phải thêm 1 cột ngày. Thêm dữ liệu thì cứ thẩy thêm file vào thư mục.
Cách tạo PQ trong file dành cho người mới tìm hiểu.


 Đã tạo file tổng hợp: {output_file}")
Đã tạo file tổng hợp: {output_file}")

